

Introduction: The Hidden Bottleneck in Scientific Progress

In modern life sciences, innovation isn’t limited by experimentation—it’s limited by data fragmentation. Across laboratories, instruments generate massive volumes of analytical data. Yet, much of this data remains isolated, inconsistent, and underutilized, making it difficult to derive meaningful insights or scale AI-driven research. According to industry observations, a large percentage of lab instruments are still not fully connected, resulting in disconnected datasets and limited analytical visibility. This is where open data standards like the Allotrope Foundation come into play—reshaping how scientific data is structured, shared, and activated.
The Core Challenge: Why Scientific Data Still Struggles to Scale
Despite rapid digital transformation, life sciences organizations continue to face persistent data challenges. Instrument heterogeneity has resulted in the use of multiple proprietary data formats, while manual data pipelines continue to increase operational overhead. Low interoperability makes cross-experiment analysis difficult, and limited data reusability restricts the long-term value of scientific information. Even with the growing adoption of FAIR principles, achieving true interoperability and reusability at scale remains a significant challenge. The root cause of these issues is the lack of standardized, machine-readable data frameworks.
Allotrope: Building a Universal Language for Scientific Data
The Allotrope Foundation is addressing this problem by developing a unified data architecture for laboratory workflows. Its framework is built on three foundational pillars: ADF (Allotrope Data Format), which enables the storage of complex experimental data and metadata in a unified structure; ADM (Allotrope Data Models), which defines how data is organized and validated; and AFO (Allotrope Ontologies), which provides standardized vocabulary for semantic consistency. Together, these components create a linked, contextual, and interoperable data ecosystem, ensuring that scientific data is not just stored—but understood and reusable.
Open Source Meets Standardization: A Game- Changer for the Industry
One of the most significant shifts in the Allotrope ecosystem is the move toward open-source implementation. Platforms like Benchling are accelerating adoption by developing open-source data converters that transform instrument-generated data into standardized formats like the Allotrope Simple Model (ASM). Why this matters: it eliminates repetitive data conversion efforts across teams, reduces dependency on vendor-specific formats, accelerates integration across lab systems, and democratizes access to standardized data tools. By making these tools openly available, organizations of all sizes can implement standardization without heavy infrastructure investment.
The Allotrope Simple Model (ASM): Bridging Complexity and Usability
The Allotrope Simple Model (ASM) plays a crucial role in making data both machine-actionable and human-readable. Built on JSON architecture, it ensures compatibility with modern systems and uses ontology-driven key-value structures for semantic clarity. ASM captures complete experimental context in a single unified object and enables machine validation, ensuring data integrity. This dual capability—readable for scientists and structured for machines—is what makes ASM a powerful enabler of AI-driven workflows.
Bridging the Gap: Aligning IT and Scientific Workflows
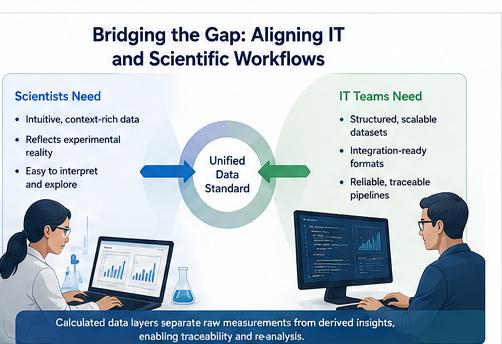
A key insight from industry adoption is that data standardization must serve both scientists and IT teams. Scientists need intuitive, context-rich data that reflects experimental reality, while data engineers and IT teams require structured, scalable, and integration-ready datasets. To address this, newer models incorporate features like calculated data layers, separating raw measurements from derived insights—improving traceability and enabling re-analysis. This alignment is critical for building end-to-end digital lab ecosystems.
From Standard to Implementation: Why Adoption Is the Real Challenge
Defining a standard is only half the battle—implementation is where real transformation happens. Challenges include a lack of awareness about the open accessibility of standards, complexity in integrating across legacy systems, resistance from stakeholders who do not immediately see value, and scalability limitations in custom-built solutions. Without practical implementation pathways, even the most advanced standards fail to deliver impact.
The Bigger Picture: AI, Automation, and Scientific Intelligence
The convergence of open standards + AI + cloud infrastructure is unlocking a new paradigm: real-time data ingestion and harmonization, automated workflows with minimal human intervention, AI models trained on high-quality, standardized datasets, and faster insights and accelerated time-to-discovery. Standardized data is no longer just an operational advantage—it’s a strategic asset for innovation.
Texium Solutions: Translating Data Standards into Business Impact

At Texium Solutions, the focus goes beyond data standardization—we enable data intelligence. By aligning with frameworks like Allotrope Foundation, Texium helps organizations build interoperable data ecosystems, implement AI-ready data architectures, enable semantic data governance, and drive digital lab transformation at scale. The result: faster R&D cycles, smarter decision-making, and scalable innovation pipelines.
Conclusion: The Shift from Data Management to Data Intelligence
The life sciences industry is transitioning from data accumulation to data activation. Open standards like Allotrope, combined with open-source innovation, are breaking down silos and enabling true interoperability across the scientific ecosystem. The future isn’t just about collecting data—it’s about making data speak a common language. And organizations that embrace this shift will lead the next wave of AI-powered scientific discovery.